23. Appendix: Some Maths#
23.1. Linear algebra#
23.1.1. Row Vector#
A row vector is a 1-dimensional array consisting of a single row of elements. For example, a row vector with three elements can be written as:
23.1.2. Column Vector#
A column vector is a 1-dimensional array consisting of a single column of elements. It can be thought of as a matrix with one column. For instance, a column vector with three elements appears as:
23.1.3. Matrix#
A matrix is a rectangular array of numbers arranged in rows and columns. For example, a matrix with two rows and three columns is shown as:
23.1.4. Transpose Operator#
The transpose of a matrix is obtained by swapping its rows with its columns. The transpose of matrix \(\mathbf{A}\) is denoted \(\mathbf{A}^T\). For the given matrix \(\mathbf{A}\), the transpose is:
23.1.5. Multiplication between Vectors#
Vector multiplication can result in either a scalar or a matrix:
Dot product: Multiplication of the transpose of a column vector \(\mathbf{a}\) with another column vector \(\mathbf{b}\) results in a scalar. This is also known as the inner product:
Outer product: The multiplication of a column vector \(\mathbf{a}\) by the transpose of another column vector \(\mathbf{b}\) results in a matrix:
23.1.6. Matrix Multiplication#
The product of two matrices \(\mathbf{A}\) and \(\mathbf{B}\) is a third matrix \(\mathbf{C}\). Each element \(c_{ij}\) of \(\mathbf{C}\) is computed as the dot product of the \(i\)-th row of \(\mathbf{A}\) and the \(j\)-th column of \(\mathbf{B}\):
23.1.7. L2-norm (Euclidean norm)#
The L2-norm of a vector \(\mathbf{x} = [x_1,\dots,x_n]^T\) (also called the Euclidean norm) measures its length and is defined as:
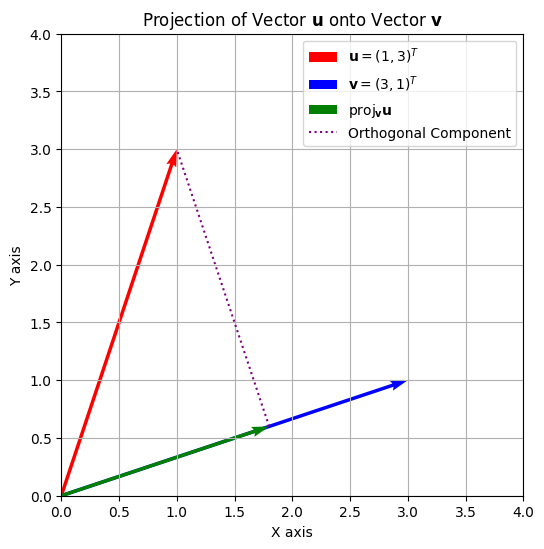
23.1.8. Projection#
The projection of vector \(\mathbf{u}\) onto vector \(\mathbf{v}\) is given by:
This represents the orthogonal projection of \(\mathbf{u}\) in the direction of \(\mathbf{v}\).
23.1.9. Eigenvalue and Eigenvector#
An eigenvalue \(\lambda\) and its corresponding eigenvector \(\mathbf{v}\) of a matrix \(\mathbf{A}\) satisfy the equation:
23.1.10. Gradient#
The gradient of a multivariable function \(f(\mathbf{x})\) is a vector of partial derivatives, which points in the direction of the steepest ascent of \(f\):
23.2. Basics of Probability#
23.2.1. Descriptive Statistics#
23.2.1.1. Mean#
The mean or expected value of a set of numbers is the average of all the values. For a set \( X = \{x_1, x_2, \dots, x_n\} \), the mean \( \mu \) is calculated as:
23.2.1.2. Variance#
The variance measures the spread of a set of numbers from their mean. For a sample set \( X \), the variance \( \sigma^2 \) using the maximum likelihood estimate is defined as:
23.2.1.3. Covariance#
Covariance is a measure of how much two random variables change together. For variables \( X \) and \( Y \), the covariance using the maximum likelihood estimate is defined as:
23.2.1.4. Probability Distributions#
23.2.1.4.1. Uniform Distribution#
The uniform distribution is a probability distribution where every outcome is equally likely over a given interval \([a, b]\). Its probability density function (pdf) is:
23.2.1.5. Normal Distribution#
The normal distribution is a probability distribution that is symmetric about the mean, showing that data near the mean are more frequent in occurrence than data far from the mean. Its pdf is given by:
23.2.1.6. Probability Density Function (PDF)#
The probability density function (pdf) of a continuous random variable is a function that describes the likelihood of the random variable taking on a specific value. The area under the pdf curve between two values represents the probability of the variable falling within that range.
23.2.1.7. Cumulative Distribution Function (CDF)#
The cumulative distribution function (cdf) of a random variable \( X \) gives the probability that \( X \) will take a value less than or equal to \( x \). It is defined as:
23.2.1.8. Expectation Value#
The expectation value of a random variable is the long-run average value of repetitions of the experiment it represents. For a random variable \( X \) with a probability function \( p(x) \), the expectation is given by:
23.2.2. Probabilistic Inference#
23.2.2.1. Likelihood#
The likelihood function expresses how well different parameter values explain the observed data. For continuous data, it is written as \(L(\theta \mid x) = p(x \mid \theta),\) and for discrete data as \(L(\theta \mid x) = \Pr(x \mid \theta).\)
Although the likelihood has the same mathematical form as a probability or density function, its interpretation differs: in the likelihood, the data (\(x\)) are fixed and (\(\theta\)) varies. The likelihood is not a probability distribution over (\(\theta\)); its role is to compare parameter values in light of the data.
23.2.2.2. Maximum Likelihood#
The maximum likelihood estimate (MLE) is the parameter value that maximizes the likelihood function:
It identifies the parameter that makes the observed data most probable (or most dense) under the model. MLEs are widely used because, under general conditions, they are consistent, efficient, and asymptotically normal. In practice, the likelihood is often maximized numerically using gradient-based or expectation–maximization algorithms.
23.2.2.3. Prior Probability#
The prior probability (\(\Pr(\theta)\)) (or density (\(p(\theta)\))) represents our beliefs about parameter values before any data are observed. Priors can encode earlier experimental knowledge, theoretical limits, or subjective expectations. When little information is available, weakly informative or noninformative priors are used to prevent the prior from dominating the inference. In continuous models, the prior is a density (\(p(\theta)\)) satisfying (\(\int p(\theta),d\theta = 1\)); in discrete models, it is a probability mass function (\(\Pr(\theta)\)) summing to one.
23.2.2.4. Posterior Probability#
After observing data (x), the prior is updated using Bayes’ theorem:
The resulting posterior distribution combines prior information with the information from the data through the likelihood. The denominator,
(or the corresponding sum for discrete variables) is the marginal likelihood or evidence, ensuring that the posterior integrates or sums to one. The posterior forms the basis for Bayesian inference, from which we can compute summaries such as the posterior mean, variance, or mode.
23.2.3. Relationships Between Random Variables#
23.2.3.1. Joint Probability Distributions#
A joint probability distribution describes the probability (or density) of two or more random variables taking specific values together. For two variables (\(X\)) and (\(Y\)),
denotes their joint distribution. From it, we can obtain:
and conditional relationships such as
23.2.3.2. Marginal Probability Distributions#
A marginal probability distribution gives the probability or density of a subset of variables, obtained by summing or integrating out the others from a joint distribution. For example, from a joint distribution of (\(X\)) and (\(Y\)):
This process is called marginalization. The resulting marginal describes the distribution of (\(X\)) alone, regardless of (\(Y\)). Marginals are useful for computing expected values, normalizing posteriors, and analyzing subsystems within larger probabilistic models. In Bayesian inference, the marginal distribution of the data,
plays a key role as the normalizing constant in Bayes’ theorem and is sometimes referred to as the evidence.